山口行治(やまぐち・ゆきはる)

株式会社ふぇの代表取締役。独自に考案した機械学習法、フェノラーニング®のビジネス展開を模索している。元ファイザージャパン・臨床開発部門バイオメトリクス部長、Pfizer Global R&D, Clinical Technologies, Director。ダイセル化学工業株式会社、呉羽化学工業株式会社の研究開発部門で勤務。ロンドン大学St.George’s Hospital Medical SchoolでPh.D取得(薬理学)。東京大学教養学部基礎科学科卒業。中学時代から西洋哲学と現代美術にはまり、テニス部の活動を楽しんだ。冒険的なエッジを好むけれども、居心地の良いニッチの発見もそれなりに得意とする。趣味は農作業。日本科学技術ジャーナリスト会議会員。
◆データ論の到達地点
人工知能(AI)はデータと電力を食べて生きている。筆者は50年間、医薬品の研究開発現場でデータを生活の糧としてきた、データを食べるAIの祖先のようなものだ。もう若くはないデータ人として、近未来のデータ文明が、少なくともディストピアとはならないように、筆者なりの「データ論」を連載して、その出発点と到達点をまとめてみた(『みんなで機械学習』第60回)。
哲学的な意味でのデータ(data)は、ラテン語・イタリア語のdare(与える)を語源として、所与または与件と解釈される。データサイエンスの実務では、データベースの変数を定義した時に、その変数に入力される値(データ)であって、データが無い場合(欠測値)もありうる。
〇個体差の問題
物理実験のデータでは、真の値と測定誤差の場合が多いけれども、生物や社会のデータでは、個体ごとに大きな個体差がある場合が多い。同一の個体で複数回測定しても、大きな経時変化(個体内変動)がある場合は、個体間の個体差(個体間変動)だけではなく、個体内変動も考慮する必要がある。病気になる人とならない人の差異だけではなく、病気になっても、治る人と治らない人の差異も考える必要があると言えば、日常的によるある話だろう。
このように、個体差を考慮する必要があるデータの場合、単純に平均値(期待値)で考えるだけでは不十分で、個体差をどのように「データ」から理解するのか、その「データ」が特定の個人にどのような意味があるのかという問題が、筆者の「データ論」の中心課題だ。
例えば新薬開発における臨床試験においては、新薬を投薬された被験者グループと、偽薬(プラセボ)を投薬された被験者グループを比較して、その試験データには個体間変動や個体内変動があるとしても、十分に信頼できる統計学的な方法によって、新薬の有効性が「ある」ことを証明する必要がある。
新薬の研究開発では、その試験「データ」から、特定の患者にとって、その薬剤がどの程度の確率で有効なのかという予後予測までは追及しない。しかし、とても高価な医薬品の場合や、重篤(じゅうとく)な症状の場合は、患者にとっては、予後予測が最重要であることは明らかだろう。
そこで、患者ごとの「個体差」を考慮して、治療法を最適化する「個の医療」が希求されるようになった。薬剤治療の予後予測では、遺伝子の個体差など、特殊な場合以外は、「データ」にもとづく判断は稀(まれ)で、医師の臨床経験に依存している。特に、老化にともなう慢性疾患の治療薬の場合では、予後に大きな個体差があって、有効性が「ある」ことを確認するだけでも大規模な臨床試験が必要となり、新薬開発の大きな足かせとなっている。
〇「データ論」で見えてきたこと
実務を離れて、哲学の文脈で「個体差」について再考してみることで、筆者としては50年間考えた予後予測の問題に突破口を見いだそうとしている。そのきっかけは、20年ほど前に、個体差を明示的にモデル化した機械学習法(フェノラーニング®)を思いつき、10年ほど前に、フェノラーニング®がAI技術の技術革新につながる可能性に気がついたことだ。
筆者の「データ論」の出発点は、「個体差は、個体差の表現の個体差である」という仮説で、個体差を増幅する「表現」の役割を重要視している。逆に考えると、個体差を表現する変数によって、増幅された個体差を理解できるということだ。この出発点から、何度も何度も堂々巡りを繰り返して、出発点がより明確になるように、上述のような文章を何度も書いてきた。読者の皆様には本当に申し訳なく思っている。
「データ論」の到達地点は、前稿の段階では、個体差を「表現」する「場所」の発見と、その「場所」が、空間的なスケールに依存しない、「くりこみ構造」となる可能性を見いだしたことで、いわば中間報告でしかなかった。その到達地点は、結局どういう意味なのか、そこから何が見えるのか、筆者自身にも理解不能だった。
〇近未来を探索する哲学的仮説
出発点は、『成長の個体差-ヒトの成長曲線をめぐって』(増山元三郎、みすず書房、1994年)と、『個性の生物学-個体差はなぜ生じるか』(大沢文夫ほか、ブルーバックス、1978年)で、とても明確だ。その途中に哲学的議論があって、上述の到達地点に至っている。
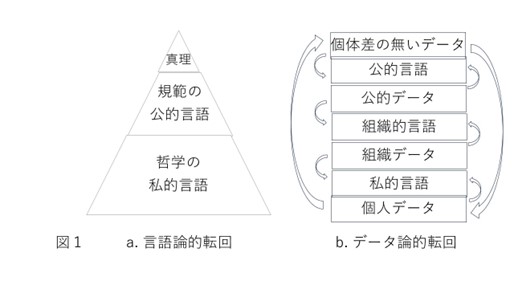
筆者自身の能力不足を言い訳にしないで、哲学的な「仮説」を提案してみたい(図1)。20世紀の哲学を、言語論的転回として総括するとして、近未来の「データ論的転回」における「言語」と「データ」の関係を図示したものだ。
図1aの「私的言語」はウィットゲンシュタインにより批判的に検討され、米国の天才哲学者ソール・A・クリプキにより、論理哲学の中心課題として再発見された未解決問題で、『ウィットゲンシュタインのパラドックス』〈黒崎宏 訳、ちくま文芸文庫、2022年)を参考にした。
図1bは筆者が勝手に「データ」と「言語」を層状に積み重ねて、しかも、「個体差の無いデータ」を「私的データ」に接続したものだ。「私的」「公的」の中間に「組織的」な「言語」または「データ」を設定して、「組織」は解像度に応じて多層に階層化される、もしくは「くりこまれる」ことを想定している。
〇言語論的転回の懐疑論
図1aで筆者が意図していることは、ピラミッドのような形での知識の体系化と、哲学と真理を分離せざるを得ない現状だ。ウィットゲンシュタインの言語論『哲学探究』(鬼界彰夫 訳、講談社、2020年)は、数学的な真理についての懐疑論から始まる。ゲーデルの不完全性定理を知っていれば、古典的「論理」は数学的な真理の全てを表現することはできないのだから、論理のような規範的言語は、哲学的な問題の全てを解決することはできないことは自明で、欧米哲学の出発点となった自著『論理哲学論考』(野矢茂樹 訳、岩波文庫 青 689-1、2003年)を批判的に修正せざるを得ない。
クリプキはより現代的な様相論理によって、論理の完全性や意味論を明確にしたけれども、筆者の勝手読みでは、ウィットゲンシュタインの懐疑論を受け入れて、哲学の置かれている状況を悲観しているように思われる。公的言語が、ジョン・ロールズの『正義論』(紀伊國屋書店、2010年)のように社会的に健全であれば、自己意識にまで遡(さかのぼ)って、哲学や文学のように懐疑的になる必要はないのかもしれない。しかし、図1aが全く機能していないことは、2025年現在では自明ともいえる。
〇データ論的転回の懐疑論
図1bには最上位の「真理」がないので、懐疑論とは無縁になるように仕組んでいる。しかし、「公的言語」から「個体差の無いデータ」に遡る矢印や、「私的言語」から「個人データ」に下降する矢印を含めていないことが、懐疑論が逆転した独断主義を封じ込める希望を表現している。どの階層においても、「言語」が「データ」に介入しないようにすることは「希望」でしかなく、おそらく現実的ではない、
「個体差の無いデータ」が「真理」だった古典的な世界に戻ることはできないけれども、「個体差の無いデータ」と「個人データ」が相互にくりこまれる世界は、より広い「真理」の世界を意味しているようにも見える。このくりこみを「個体差をキャンセル」する可能性として、新しい作業仮説を見いだした。
- 個体差をキャンセルする
無理やり、哲学的な意味での出発点と到達地点を図示(図1aと図1b)してみた。到達地点での実務的な課題は「老化の個体差」であって、加齢とともに発症率が増加する慢性疾患の治療薬の開発を志向している。個体差を表現する変数、特に「場所」(すなわち身体と生活)を表現する変数を構成することができれば、見かけの大きな個体差を打ち消して(増幅の逆)、均質な集団として治療の対象とする方法が見つかることを期待している。
老人における栄養学的データを「aging commons」として集積すれば、老化に関連する「個の医療」の背景データとして、世界の医療の技術革新を推進する基盤技術となる可能性がある。もう若くはない日本社会にふさわしい課題だろう。
「個体差を増幅する仕組みをキャンセル」するために、老人たちから若年世代への「データ」の贈り物となれば、来たるべきデータ文明への希望も見えてくるだろう。個体差を考慮する個の医療(パーソナルヘルスケア)の逆転発想で、個体差をくりこんで(renormalize)キャンセルするreパーソナルヘルスケア(renormalized personal healthcare)の新しい景色が見えてきた。
現実に戻ると、その経済効果は世界的に数百兆円になるかもしれないけれども、その実現には、少なくとも数百億円は必要で、初期の探索的研究の成功確率は1/10,000程度と見積もれる。この確率が、人類の生存確率ではないことを祈りたい。
◆交通事故のオープンデータ
IBMクラウドの機械学習プラットホーム(SPSS Modeler)を使って、機械学習の脱学習を始めるために、既成概念を脱学習するデータを探していた。機械学習の課題としては、ネット販売のデータから売り上げ予測をしたり、健康関連のデータから治療法を検討したりする課題が多い。
しかし、これらの機械学習における実用的な課題では、データの入手が困難で、データの背景も不十分にしか説明されていない場合が多い。筆者の経験では、このような課題の場合、導きたい結論が先に仮定されていて、データで事後的に説明しているように疑いたくなる。少なくとも、結論を常識的に解釈できる場合が多い。脱学習するためには、こういったデータ解析の結論を疑う必要があるので、よくある機械学習の学習用データでは不適切だ。
日本でも、政府関係のオープンデータが増えてきている。そこで、警察庁が公開している交通事故統計情報のオープンデータ(https://www.npa.go.jp/publications/statistics/koutsuu/opendata/index_opendata.html)を使うことにしたい。警察庁としては、事故多発地点を特定して、道路交通システムとしての対策を考えることが主要な目的だろう。実際に、事故多発地点を特定するための、空間統計学的なツール(緯度経度の四角形または距離円での抽出アルゴリズム)と、地図データとの連携機能が提供されている。
筆者の脱学習課題は、自動車産業が製造物責任を公開データからどのように読み取るのか、無視しているのかということを議論することだ。製薬産業においては、死亡事例を含む有害事象を、企業が責任をもって収集し、全世界に公開するだけではなく、データベースを定期的に解析して、安全性報告を作成している。自動車が大量生産されなければ、交通事故は社会問題とはならないし、運転者の責任や警察庁の対策も不必要なので、最初に問われるべきは、製造物責任だろう。
筆者のように、製薬企業で有害事象のデータを解析した経験から、どの程度の脱学習が出来るのか、自分自身への挑戦でもある。次回からは、ペースを落として、一歩一歩、実況中継してゆきたい。
--------------------------------------

『みんなで機械学習』は中小企業のビジネスに役立つデータ解析を、みんなと学習します。技術的な内容は、「ニュース屋台村」にはコメントしないでください。「株式会社ふぇの」で、フェノラーニング®を実装する試みを開始しました(yukiharu.yamaguchi$$$phenolearning.com)










[…] を理解することが困難だった。そこで、前稿(『みんなで機械学習』第62回、https://www.newsyataimura.com/yamaguchi-145/ )では、機械学習の学習と、交通事故の脱学習をめざして、警察庁から提供 […]