山口行治(やまぐち・ゆきはる)

株式会社ふぇの代表取締役。独自に考案した機械学習法、フェノラーニング®のビジネス展開を模索している。元ファイザージャパン・臨床開発部門バイオメトリクス部長、Pfizer Global R&D, Clinical Technologies, Director。ダイセル化学工業株式会社、呉羽化学工業株式会社の研究開発部門で勤務。ロンドン大学St.George’s Hospital Medical SchoolでPh.D取得(薬理学)。東京大学教養学部基礎科学科卒業。中学時代から西洋哲学と現代美術にはまり、テニス部の活動を楽しんだ。冒険的なエッジを好むけれども、居心地の良いニッチの発見もそれなりに得意とする。趣味は農作業。日本科学技術ジャーナリスト会議会員。
◆宴の後の人工知能
いよいよ、AI(人工知能)バブルが弾けそうだ。AI企業の技術革新が低水準になって、株価が低迷するだけならば、実体経済への影響は限定的だろう。しかし、低水準なAI技術で多くの雇用が失われる負の経済効果は、底なし沼かもしれない。
ゲームなどの特定の技術領域で、AI技術が人間の知能を超えることは確実で、ゲームのプロとAIの共生が実現されている。知的労働者の一般的な知能水準に、AI技術が到達するのも時間の問題だ。多くの人びとが、AI技術を日常的に利用することで、AI技術は進歩するけれども、人間の知能は退化するとしたら、AI技術が人類の未来にもたらす問題は、根が深く深刻だ。
日常的なビジネス関連の問題では、厳密な論理的な意味での、計算可能な問題よりも、計算不可能な問題のほうが多い。ビジネスにおけるAIの役割は、確率的な予測が重要になる。人びとが問題を解決しようとする意欲を失い、新たな問題の発見につながる冒険を避け続けたらどうなるのだろうか。会社や役所ではAIが最適解を求め、市場は確率的に運用されて、安価で低品質なサービスが提供されるようになるだろう。もしくは、市場外で、高価で贅沢(ぜいたく)なサービスが、ごく一部の権力者に独占されるのだろうか。
AI技術が成熟して産業利用される近未来が、ディストピアとなることは容易に想像できる。ユートピアではなくても、少なくとも新しい文明として、西欧中心の近代文明とは別の文明が登場する可能性は無いのだろうか。
現在のAI技術を頂点とする、技術思想としての近代文明は、言語や数理などによる「大域的」な知識を追求してきた。科学における「普遍的な真理」を信じることで、数学的な定理や物理法則など、専門家による理論的な体系化が、知識の「基礎づけ主義」となった。
知識の「基礎づけ主義」という、近代文明の高揚感は、20世紀後半に、ゲーデルの不完全性定理や、チューリングのプログラム停止問題によって、針の穴のような、論理的な基礎づけを拒否する怪物命題が見いだされ、立ち止まる。ついに21世紀前半では、大規模言語モデル(LLM)が、言語やプログラムコードの「大域的」な知識を、「確率的」に、「普遍的な真理」とは無関係に、把握することに成功した。すなわち、AI技術は、技術思想としては、近代文明の終わりの始まりなのだ。
筆者は近未来のデータ文明を夢想して、この論考を続けている。現在のAI技術が取り扱うデータは、ビッグデータで、大域的な知識に関連するデータだ。局所的な知識に関連するデータは、スモールデータであって、「普遍的な真理」ではないけれども、個人的には役立つデータだ。多分、大域的な知識よりも、局所的な知識のほうが、はるかに大量に存在していて、しかも個人や地域にとっては重要な知識だ。この局所的な知識をデータから機械学習する方法を、個体差の機械学習フェノラーニング®として探索している。局所的な知識ではあっても、関連する局所的な知識を接続することができるように、「データモデル」を設計することが重要なポイントになる。大量の局所的な知識を接続すると、それぞれの局所的な知識が中心(局所座標系)となる知識の多様体になる。
筆者は、局所的な知識の機械学習法として、2010年にクリニカルトライアルマップを特許出願している(特願2010-021550、『みんなで機械学習』第65回「IBMクラウド実況中継(その3) 生成AIがバカすぎて」、https://www.newsyataimura.com/yamaguchi-148/#more-22431 )。ビッグデータの機械学習が発展途上で、LLMや生成AIは誕生していない時代だ。学習結果をネットワークグラフで視覚的に表現した。しかし、学習用の局所的な(問題を絞った)データセットごとに、プログラマーがパラメーターを調整していた。計算にはパソコンで一晩かかっていたので、多数の局所的な知識を接続することは絶望的だった。パソコンのCPU(Central Processing Unit=中央演算処理装置)だけではなく、現在のAIで多用されるGPU(Graphics Processing Unit)やNPU(Neural Processing Unit)を使えば、計算時間は1時間以内になるだろう。データモデルも、ClinicalTrials.govというデータベースに固有のものではなく、グラフ理論で抽象的に表現することも可能だ。そして、15年後に、フェノラーニング®として、再度、局所的な(個体差が無視できない)知識の機械学習に挑戦している。
グローバルビジネスとして、AIビジネスが世界を支配するためには、大域的な知識を振りかざす、現在のAI技術が都合が良い。顧客の個体差も、母集団からの外れ値として処理できる。全ての個体が中心となるような、世界支配にとって都合が悪い技術は、破壊してしまうのが近代文明だ。地球は丸くても、あくまで欧米中心のグローバルビジネスでしかない。
筆者としては、近代文明の覇権争いには関与したく無いので、フェノラーニング®は未完の技術のままで、技術思想として追求することにしている。しかし、個体差を無視できない「データ」に関する興味は失っていない。個体差としか言いようがない、訳のわからない「データ」に、50年間つきあってきた。AIバブルの宴が弾けた後には、多くの社会問題が残されて、大量の局所的なデータがゴミの山となるだろう。その時こそ、フェノラーニング®で、ゴミ「データ」の清掃作業を効率化することにしよう。役割を失った生活世界のスモールデータが、データ文明の勝手口になる。
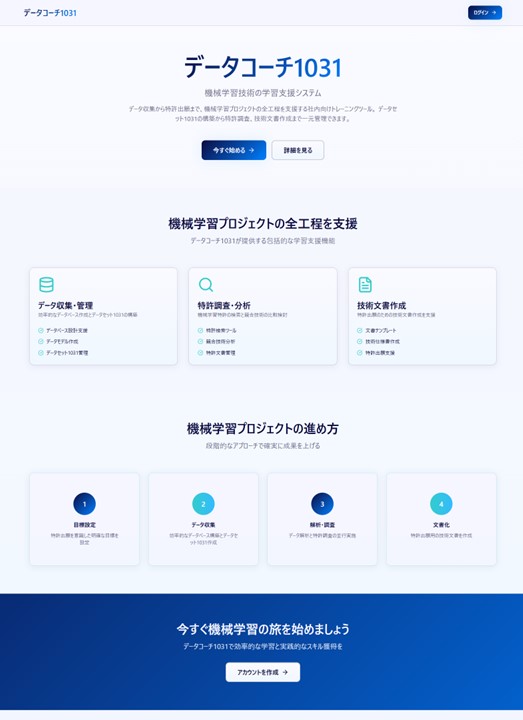
〇 Lovable実況中継-2 Supabaseでバックエンドのデータベースを作成する
前回はLovableに以下のプロンプトを与えて実行した。「Webアプリを作ってください。5人程度のグループのプロジェクトで、プロジェクトの目的を明確にしてから、データを収集して、データベースを作成します。数百件程度の小さいデータを解析して、主目的に関連する個体差の要因となる変数を5から10個程度選出します。解析結果のデータモデルを特許出願することを目的とする機械学習プロジェクトのWebアプリです。」
Lovableは上記の指示を「5人程度のグループでの機械学習研究プロジェクト管理Webアプリを作成します」と理解した。このWebアプリを命名する必要がある。プロジェクト管理が主目的ではなく、機械学習技術を学習するためのコーチング(学習支援)が主目的だ。
特許出願を目指すということで、「研究」プロジェクトと解釈しているのは、気が利いているようであっても、あまりに常識的だ。多分、「データモデル」を特許出願するという意味が、AIにとっては不明瞭なのだろう。
ビジネス関連特許は、ビジネスに情報技術(IT)を使う新規な方法を「発明」ととらえる。ITではなく、ビジネスに「データ」を使う新規な方法を「データモデル」の発明と考えている。特許では、「データ」そのものを保護できないので、「データモデル」として抽象化する工夫だ。
このような反省をして、最初の試行プロンプトを修正してみよう。「Webアプリを作ってください。5人程度のユーザーがログインして使う社内プロジェクト用のWebアプリで、データコーチ1031という名称です。このWebアプリでは、1人のコーチ役が機械学習技術の学習支援を行います。学習の目的を明確にしてから、データを収集して、データベースを作成します。数百件程度の小さいデータをデータベースから抽出して、データセット1031という名称の解析用データセットを作成します。機械学習技術に関連する特許を調査して、データセット1031を使って比較検討します。自社ビジネスにとって有益な結果が得られた場合、機械学習技術をビジネス応用する新規な方法として、データセット1031のデータモデルを特許出願できるように、技術文書としてまとめます。特許調査や特許出願用の技術文書の作成も、Webアプリ(データコーチ1031)が支援します」。上記の修正プロンプトに、以下の詳細な指示を追記する。
「<設計概要>
社内用の機械学習技術の学習支援ツールを作成します。データ収集から特許出願まで、機械学習プロジェクトの全工程をオンジョブ・トレーニングするシステム(名称はデータコーチ1031)です。
<実装する機能>
特許出願を意識した目標設定
データ収集のためのデータベース作成・管理
データ定義を明確に記載したデータモデルの作成
データベースから解析用データセット(名称はデータセット1031)を作成
データ解析結果を共有するダッシュボード
機械学習特許の検索ツールと特許文書管理
特許出願のための技術文書作成支援
パスワードによるログイン管理を含むチームメンバー管理
<デザインコンセプト>
科学的な印象の青系グラデーション配色
データ分析に最適化されたクリーンなカードUI
プロジェクト状況が一目でわかるダッシュボード
レスポンシブ対応の現代的なインターフェース」
この修正プロンプトを与えると、Lovableは10分ほどで、添付したランディングページを作成した。これは単なる画像ではなく、およそ2000行のコードが、14個のファイルとして作成された動作可能なWebアプリだ。しかも、データベースと連携する部分はSQL言語でコーディングされている。ログイン関連でのSupabseのセキュリティー設定が不十分であるため、Lovableはエラーを検出して、自動的にコードの修正を行った。多分、データベース関連の機能は不十分で、何回も修正が必要だろう。その修正も、エラーメッセージを読んで、指示を与えれば、Lovableが行ってくれる。
それにしても、Lavableのコード作成の能力とスピード感には驚かされる。AI技術で失われる営業職は、営業用のWebアプリに変身して、営業担当者がLovableに指示を与えてWebアプリを作成する。AI技術で本当に失われる雇用は、Webアプリを作成するプログラマーだ。特許を出願するのも研究者ではなく、営業職がAIを使って大量の技術文書を作成すると、弁理士がAIを使って迅速に特許出願する時代となる。冒険を好む研究者を雇用する経営者はいなくなるので、研究者自身が経営者になって、冒険を継続する。ユートピアではないけれども、AIとともに、日常的な勝手口を出入りしながら、生き延びてゆこう。
- 閑話コラム記事15 個体差の技術哲学
哲学は社会制度に制約されない議論を展開する。場合によっては、社会制度の変革を提案する。現在の技術哲学も、哲学であることに変わりはない。
一方で、技術は社会制度を前提として開発される。現在の社会制度では、技術的発明は特許出願され、技術的発明の新規性・進歩性・有用性(産業上の利用可能性)が審査される。特許文書は、発明の背景となる有用性と進歩性を、技術思想の中に位置づける。特許としての「請求事項」を明確にして、請求事項の裏付けとなる事実を実施例に記載する。
現在の技術哲学は、過去の哲学にこだわっていて、特許文書を考察対象としていない。すなわち、技術思想なき技術哲学だ。AI時代の技術哲学では、特許文書をAIが調査研究して、哲学的な議論を展開したい。AIの哲学が、AI倫理に限定されずに、AI技術の技術思想そのものを批判的に検討して、AI技術の限界を見定める。
シンガポール発のユニコーン企業PatSnapが、世界170か国以上の2億件の特許データと2億件の技術文献をLLM(大規模言語モデル)で機械学習して、高度な知財サービスを展開している(https://www.jetro.go.jp/biz/areareports/2024/74798653019de35f.html)。顧客は1万社以上、日本でも大手製薬企業のほとんどが導入している。多分、技術哲学の哲学者が、AIに関する技術思想を調査研究する目的では、PatSnapの機能で十分だ。残念ながら、PatSnapは哲学者が気軽に使える料金ではない。やはり、技術哲学のためのAIツールが必要だ。
筆者が推進しているフェノラーニング®は技術哲学のためのAIツールではないけれども、個体差が無視できないデータの機械学習を主目的としているので、「個体差の技術哲学」であれば、フェノラーニング®の学習資料にはなりそうだ。
個体差の技術哲学について、次回も考えてみたい。
--------------------------------------

『みんなで機械学習』は中小企業のビジネスに役立つデータ解析を、みんなと学習します。技術的な内容は、「ニュース屋台村」にはコメントしないでください。「株式会社ふぇの」で、フェノラーニング®を実装する試みを開始しました。










コメントを残す