山口行治(やまぐち・ゆきはる)

株式会社ふぇの代表取締役。独自に考案した機械学習法、フェノラーニング®のビジネス展開を模索している。元ファイザージャパン・臨床開発部門バイオメトリクス部長、Pfizer Global R&D, Clinical Technologies, Director。ダイセル化学工業株式会社、呉羽化学工業株式会社の研究開発部門で勤務。ロンドン大学St.George’s Hospital Medical SchoolでPh.D取得(薬理学)。東京大学教養学部基礎科学科卒業。中学時代から西洋哲学と現代美術にはまり、テニス部の活動を楽しんだ。冒険的なエッジを好むけれども、居心地の良いニッチの発見もそれなりに得意とする。趣味は農作業。日本科学技術ジャーナリスト会議会員。
◆生成AIがバカすぎて
過去記事(『みんなで機械学習』第59回、https://www.newsyataimura.com/yamaguchi-142/)を引用する。「『店長がバカすぎて』(早見和真、角川春樹事務所、2019年)は、書店を舞台とする大衆小説だ。小説の劇中劇を巧(たく)みに構築して、社長がバカすぎてから、自分自身がバカすぎてまで、スケーリング則により、小説の作者も含めて、みんながバカすぎる生活を、愛と希望で描いている。大統領がバカすぎてでも、裁判長がバカすぎてでも、スケーリング則は普遍的に成立する」……と訳のわからない文章を書いた。生成AI(人工知能)も、バカすぎるぐらいがちょうど良いのかもしれない。生成AIの劇中劇は興味深い。
IBMクラウドには、オープンソースソフトウェア(OSS)として開発・公開された、多数の大規模言語モデル(LLM)が提供されている。生成AIはLLMをコア技術として、文章だけではなく、画像や動画まで取り扱えるようになっている。言語で説明したり、批評したりすることができるデジタル情報であれば、言語による指示(プロンプト)によって、新規のデジタル情報を人工的に生成することができる。
AIソフトウェアを記述するPYTHONプログラムのソースコードを、生成AIが作成できるようになった。膨大なOSSのソースコードを、LLMが機械学習し続けている。これは、生成AIの劇中劇のようなものだ。
生成AIが脚光を浴びたのは、画像の生成や、チャットボットでの会話の生成だった。最近の生成AIは、論理的な推論能力が付与されて、画像や会話の出来栄えだけではなく、文脈に依存した深い考察や調査が可能になっている。ビジネスで使うためには、公開情報だけではなく、社内文書を正確に理解する必要があるため、事前に学習した生成AIのLLMを、RAG(Retrieval-Augmented Generation)という検索技術と組み合わせて使っていた。
Googleが推進している生成AI、GEMINIの最新版(gemini 2.5 pro)では、問い合わせ(プロンプト)に使う情報量が、最大3000ファイル、ファイルあたりの最大1000ページと、膨大なものになり、RAGのような検索だけではなく、プロンプト情報を詳細に分析・整理した後に、回答を生成するようになった。例えば、3000件の特許を読んで、技術動向を整理してから、質問に回答するとすれば、ビジネスに役立つというよりも、AIにビジネスを教えてもらう感覚だ。
生成AIの技術的な進歩が、劇中劇となって、ほぼすべてのビジネスを革新している。生成AIは賢くなりすぎてしまったようだ。生成AIが革新するビジネスには、愛も希望もなく、危険な落とし穴と陰謀が溢(あふ)れているように思える。
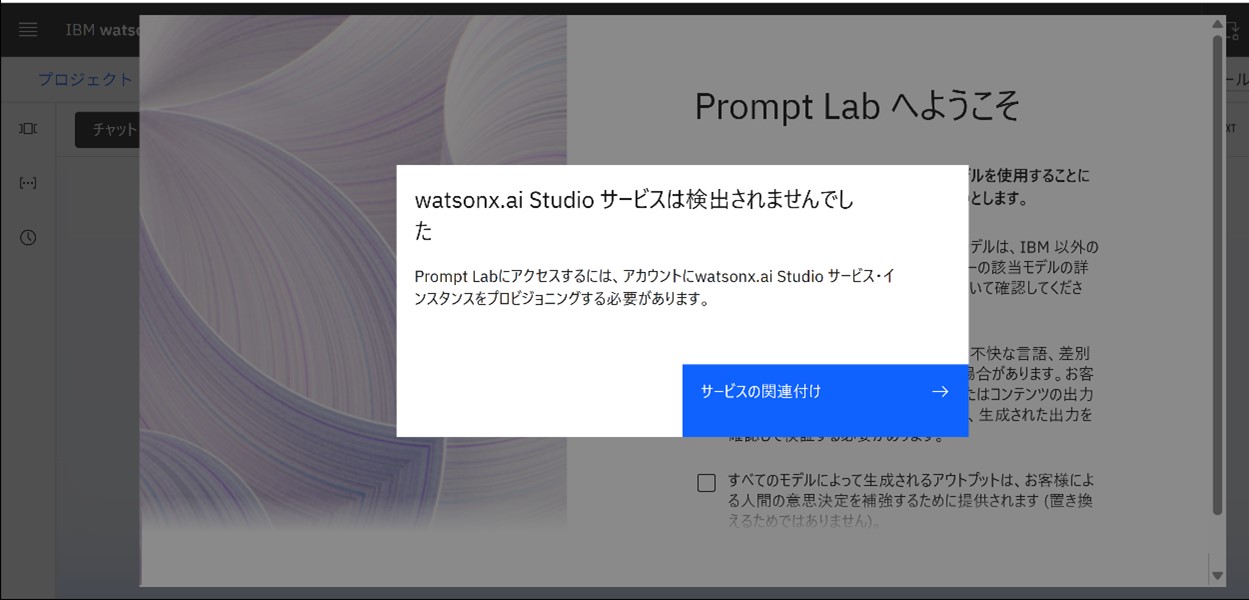
〇IBMクラウド実況中継-3 生成AIを使えなかった
私のIBMクラウドアカウントは無料版で、SPSS Modelerを使う目的で設定したため、生成AIを使えなかった。生成AIを使うだけであれば、ChatGPTなどの無料生成AIサービスで十分だろう。IBMクラウドのwatsonxでは、自分で用意したドキュメント類を使ってRAGを作ったり、複数のAIエージェントを使う情報分析ツールを開発できたりするので、生成AIのビジネス応用が可能になる。個体差をモデル化するフェノラーニング®をSPSSで開発してから、生成AIと連携・統合して、個体差が大きい健康データを機械学習する計画だ。営業支援や販売促進などの通常のビジネスであれば、GoogleのGEMINIのように、汎用(はんよう)で強力な生成AIクラウドサービスで十分だろう。
最新の特許を分析して、競合する技術と比較検討するなどの、技術的に高度な分析を生成AIで行うためには、分析結果を可視化したり、要約したりする複数のツール類と組み合わせる必要があるため、近いうちに再度、IBMクラウドで生成AIを使ってみたい。
IBMクラウドはOSSをたくさん集めているので、DeepSeekやQwenなどの中国系のAIソフトウェアを試すことができるのも魅力だ。実用的なAIプログラムを開発するのであれば、中国系のAIソフトウェアは小型で高性能なので、検討に値する。生成AIのセキュリティーは、中国製でも米国製でも、全く信用できないので、別途、AIセキュリティーツールを使って、運用時に監視することにしよう。
現時点での筆者の目的は、「みんなで機械学習」することなので、非営利活動として、別途、IBMクラウドのアカウントを作成して、実況中継を継続することにする。
◆閑話コラム記事5 lens.orgは特許情報と学術情報を関連づけた無料/有償サービス
筆者は30年以上、特許情報はPatentscopeで、学術情報はPubmedで検索してきた。それぞれの検索式は手入力で、検索結果も100件程度に目を通すのが限界だった。特許情報と学術情報の関連づけは、筆者の脳内ブラックボックスで実行していた。
最近、特許情報と学術情報を関連づけたlens.orgのサービスを知って、20年前からこのサービスを開発しているオーストラリアのグループを尊敬している。OSSの統計解析ソフトRを開発したのはニュージーランドのグループだった。AI分野では中国のグループの活躍が目覚ましい。世界中の研究者は、世界中の研究者に依存している。
インターネットの公開情報をデータ処理して、新しい創薬アイデアを見つける試みとして、16年前に、治験のデータベースClinicalTrials.govを検索して分析する情報ツール、クリニカルトライアルマップを開発した経験がある。
クリニカルトライアルマップは、Mathematicaで開発して、特許出願した(特願2010-021550)。当時は、もちろん生成AIは存在しないし、PYTHONも普及していなくて、機械学習関連では、Mathematicaが最高のプログラミングツールだった。特許出願しても、技術を独占してビジネスにすることが目的ではない。技術を公開して、バイオマーカー関連の創薬ビジネスを推進することが目的だった。
その時の経験から、バイオマーカービジネスの出口戦略、すなわちバイオマーカー開発が製薬企業や公的な支援から経済的に自立して、独自の市場を形成するするためには、より広範な機械学習ビジネスと連携する戦略に思い至った。それから10年ほど考えて、フェノラーニング®のビジネス提案を始めている。
生成AIは、脳の数理モデルであるディープラーニングから発展したので、画像や文字情報など、人間が理解しうる、意味のある情報のデータ処理を得意としている。
筆者のように、意味があるのかどうかよくわからない、自然科学系のデータから、探索的に意味らしきものを発見したり、多くの場合は、データの間違いを探す仕事をしたりしていると、このような仕事は人間が得意ではなく、機械学習の力を借りたくなる。
ディープラーニングは、現在入手可能な、意味があって、価値がありそうなデータを、ほぼ全て機械学習してしまった。フェノラーニング®では、バイオマーカーのように、医学的にはよくわからないけれども、実用的には意味がありそうなデータを、リアルタイムに大量に与えて機械学習することを想定している。
新たなデータの世界を探索するデータAIが、データ文明の入り口になるのか、生成AIが近代文明の言語資産を消費し尽くして衰退するのか、近未来への岐路は論理的ではなく、少なくとも4次元以上の高次元空間の想像力で、多数の入り口と出口を発見して冒険する必要がありそうだ。
--------------------------------------

『みんなで機械学習』は中小企業のビジネスに役立つデータ解析を、みんなと学習します。技術的な内容は、「ニュース屋台村」にはコメントしないでください。「株式会社ふぇの」で、フェノラーニング®を実装する試みを開始しました(yukiharu.yamaguchi$$$phenolearning.com)










[…] 前稿第65回(「IBMクラウド実況中継(その3) 生成AIがバカすぎて」https://www.newsyataimura.com/yamaguchi-148/#more-22431 )は「新たなデータの世界を探索するデータAIが、データ文明の入り口にな […]
[…] 械学習』第65回「IBMクラウド実況中継(その3) 生成AIがバカすぎて」、https://www.newsyataimura.com/yamaguchi-148/#more-22431 )。ビッグデータの機械学習が発展途上で、LLMや生成AIは誕生していな […]